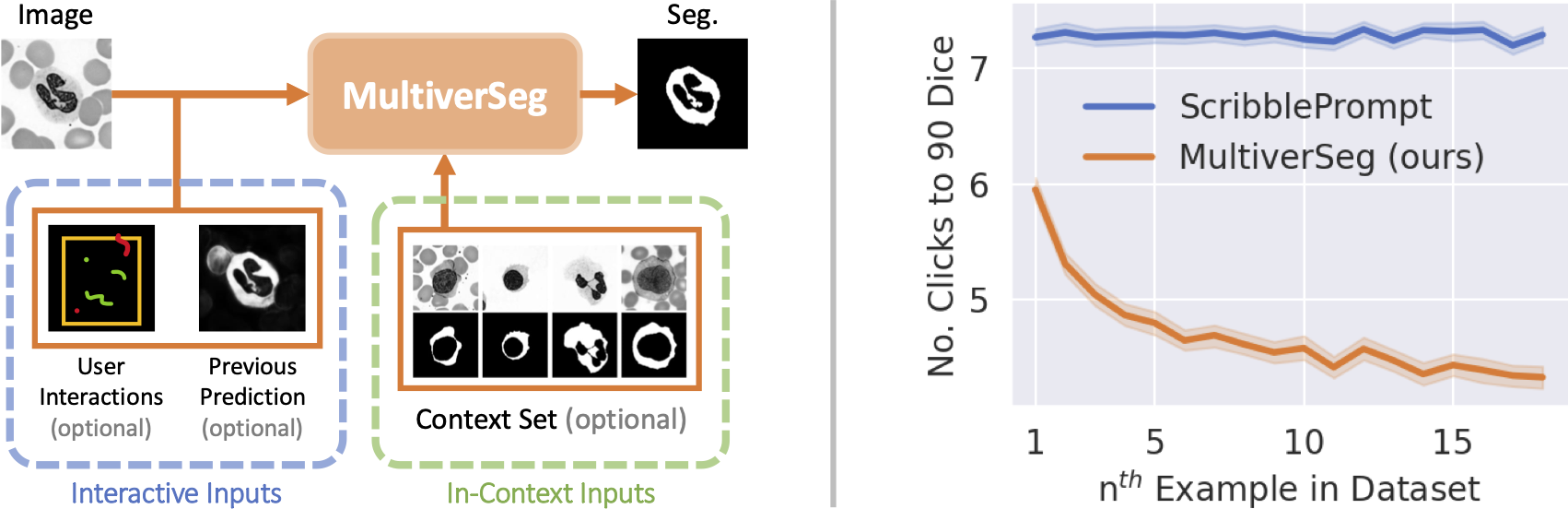
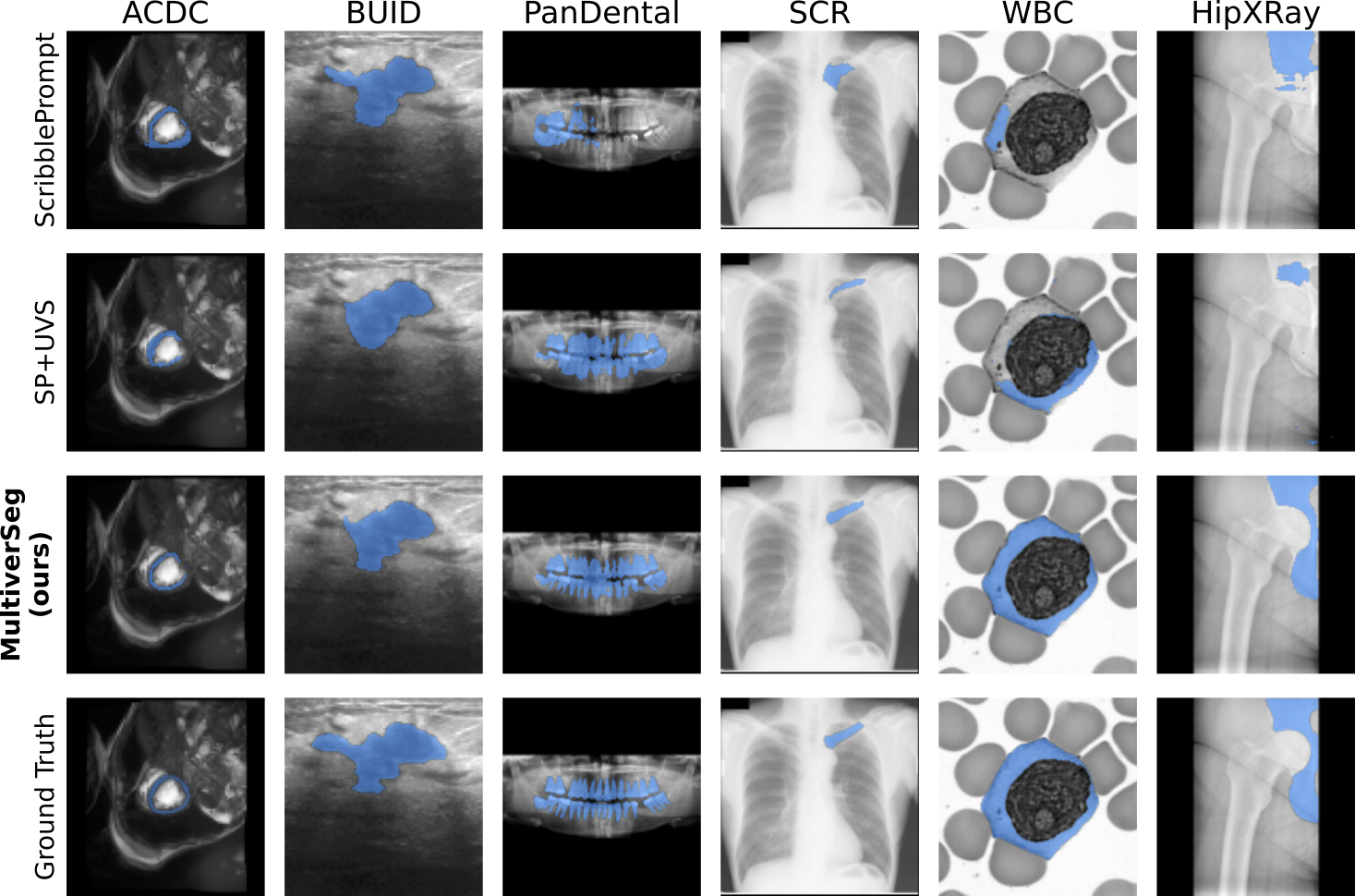
Medical researchers and clinicians often need to perform novel segmentation tasks on a set of related images. Existing methods for segmenting a new dataset are either interactive, requiring substantial human effort for each image, or require an existing set of manually labeled images.
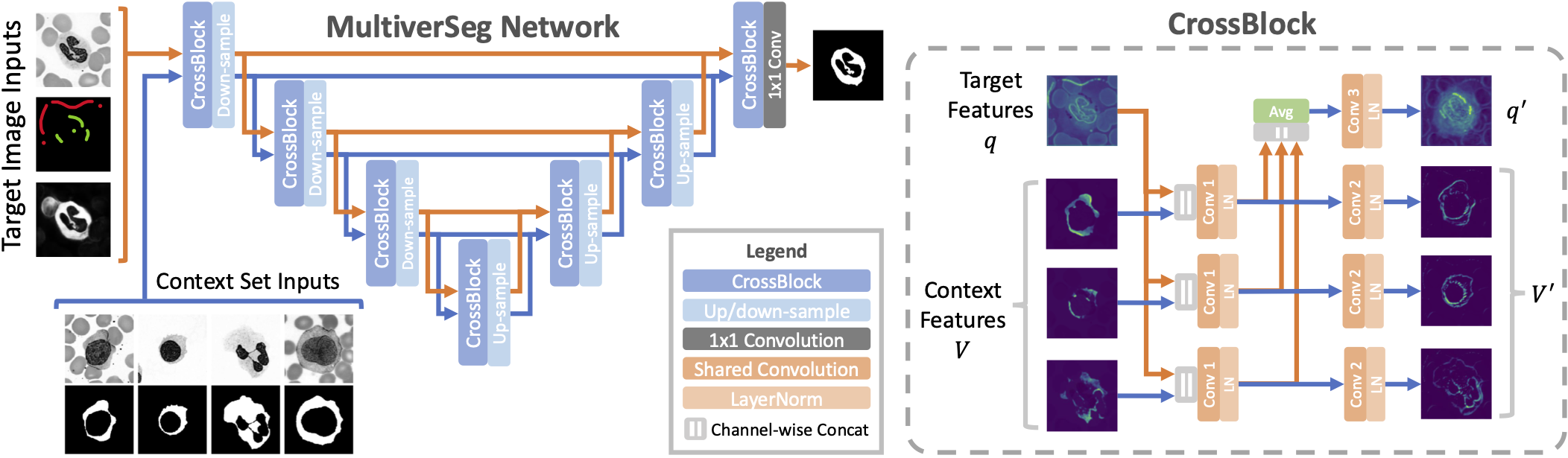
We introduce a system, MultiverSeg, that enables practitioners to rapidly segment an entire new dataset without requiring access to any existing labeled data from that task or domain. Along with the image to segment, the model takes user interactions such as clicks, bounding boxes or scribbles as input, and predicts a segmentation. As the user segments more images, those images and segmentations become additional inputs to the model, providing context. As the context set of labeled images grows, the number of interactions required to segment each new image decreases.
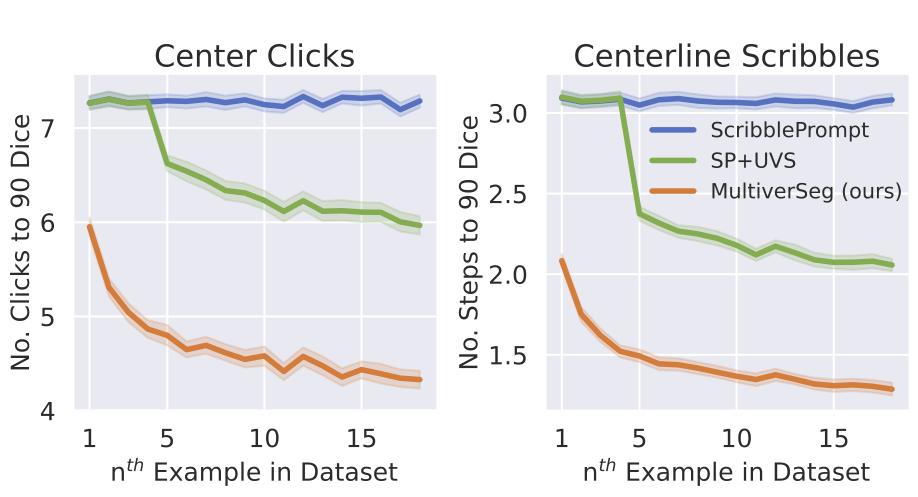
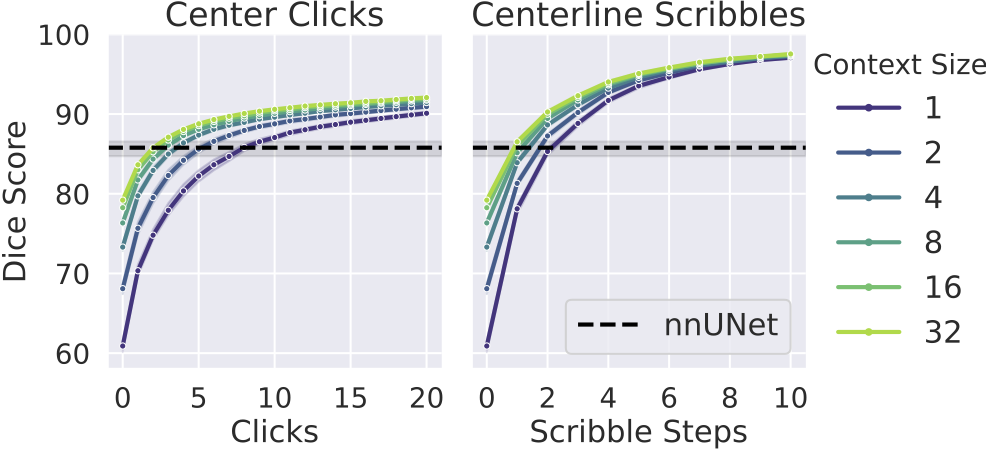
We demonstrate that MultiverSeg enables users to interactively segment new datasets efficiently, by amortizing the number of interactions per image to achieve an accurate segmentation. Compared to using a state-of-the-art interactive segmentation method, using MultiverSeg reduced the total number of clicks by 36% and scribble steps by 25% to achieve 90% Dice on sets of images from unseen tasks.